As developers we are taught that the lack of process and coding standards are the reason for project failures. The majority of us blindly believe it without really examining if this is the truth. Let me take you on a trip down the rabbit hole and let’s explore the truth of the matter.
Coding standards and process are usually the first thing that management wants to review when a project starts to show any of the following:
- bad system performance
- slow developer performance
- bug explosion
- long delivery times,
- developers unable to do proper estimations
The article that follows attempts to draw similarities between software development and the second law of thermodynamics from statistical point of view.
Management says we need more process and coding standards!
The reason for this is usually cause they do not know what else to do and feel desperate, something needs to be done! Normally a business does not really care about coding standards or any process – they simply want to get their product to the market as quickly as possible. It is the developers that care about process and coding standards as they need to work on each other’s code.
What most managers don’t realize is that it is possible to write the prettiest code and follow the best process in the market, and it can still result in bad performance, slow delivery and ultimately project failure. Developers usually know themselves that more coding standards or processes won’t solve these problems but are themselves ignorant to what to do to fix the situation and because they feel like they are failing they end up adding more standards, more processes and review cycles, slowing things down even more.
Process and coding standards are not to blame.
Having process and coding standards are not a bad thing, it assist with the job cycle, code maintenance and code readability. It allows one developer to work on the code of another as the ‘style’ is the same. You can not fix a bad design by coding in a nice style or adjust your process , that is like painting your house to hide the cracks and the leaky pipes in the walls.
In small projects, simple coding standards paired with code reviews will go a far way to keep a system maintainable but the same is not true in large system.
The bullet list of symptoms listed higher up in the article are usually a result of the invisible problem that no one thinks about… coupling. Coupling is caused by having too many components or coding for code for re-use.
So where / what is the problem?
- Overuse of coding for ‘re-use’ ( Inheritance & Composition )
- too many technologies.
- too many components.
- too many hidden / invisible / unknown connections or dependencies.
Every developer is taught that code re-use is good and that one should look for abstraction in structures as to code something once and then re-use it elsewhere. This is the beginning of the problem.
Let’s assume from this point on that we will be using the best coding standards and that we will be doing peer reviews going forward.
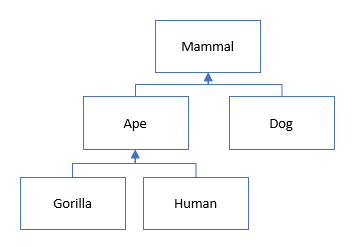
The diagram above is a rudimentary example that is often used to explain inheritance. What they do not tell you when using these type of examples is that in real life these never change but our code on the other hand “evolves” and changes constantly due to the amount of energy spent by developers as a result of changing requirements.
This results in the code base moving from a low entropy state to a high entropy state which means it becomes more disordered with time. The amount of permutations and outcomes are astronomical if you take the possible combination between classes and components into consideration.
Inheritance and composition is powerful and a necessary evil if one is designing for code re-use but the down side is that it results in coupling that no-one ever thinks about. One piece of code has to be referenced and carried along by another. Coupling is the result of the combination of one object with another. Having high coupling or many dependencies in technology is not a good thing as this causes complexity and slows things down.
The complexity is not in the code but in all the relationships between the structures.
Coupling causes chaos!
With time this results in complexities between assemblies and modules that our human mind can not comprehend. Changing the code in one area can affect the behavior of the application in another intentionally and unintentionally.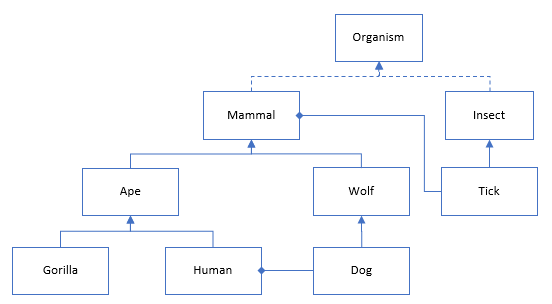
Looking at the first image it looked nice, clean and structured but as time goes on and we extend the structures and more and more relationships are created (coupling) which results in the system becoming more and more complex.
This is why it becomes difficult to add new features to projects or to do estimations as we can not process or comprehend all the relationships. It all comes down to entropy, as time progress in the life time of a project, more and more code is added resulting in more variables, more structures and more possible combinations. The project moves from an ordered structure with low entropy to a high entropy structured mess.
So here is a where the problem comes in.
Imagine we continue with this class structure but at some point we need to change the behavior of the Mammal class. In real life a mammal will not change but this happens in code. What you find now is that you have dependent classes that expects the ‘Mammal’ class to work in a certain way but you need to change the ‘Mammal’ class to support a new feature. …now we are forced to introduce a ‘If statement’ meaning that you have just added even more invisible complexity because we are trying to re-use. Before making the code change you now have to consider all the relationships to the class and this is where the complexity lies. If you miss something you introduce a bug. If you don’t see it all during your estimations your will discover it at compile time…Oops its taking longer than expected. The mammal class is now having to behave in 2 different ways. In a large system it would be beter to make a copy of mammal and call it mammal2 allowing it to evolve freely from the other. Now if a developer needs to make a change he has one place to change and only one behavior to consider. This is what micro services kinda try to do.
This is why it is faster and easier to develop features in smaller systems or to rather start from scratch. There are no or very little coupling to consider. The system is in a low entropy state.
It makes testing difficult
The more re-usable classes you have , the more components you, the more technology you have the more possible combinations you have. This complicates testing. Testing one class by itself is easy but as soon as you start combining results of the classes the complexity goes up and so does the possible outcomes.
n! = n x (n-1) x (n-2) x … x 1
Our structured mess!
Even if we follow the best coding standards and practice good Object orientation we will eventually end up with something like this … a structured mess really very similar to unstructured spaghetti code.
The image above is just a random image of internet to get my point across.
So… imagine you do not know the code base, you only see a portion of code that you will be working one… how long will it take you to make a change?
Once a project has reached this level a few things happen.
- Delivery starts to decline as the complexity of the structure goes up.
- Developer workload goes up, they spend more and more time doing less.
- Developers are stuck, they can not easily change something without affecting something else.
- Bugs are introduced in unrelated modules.
- It becomes almost impossible to give estimations on tasks – how deep does this rabbit hole go?
- Management gets involved, usually aggravating the situation by wanting to punish the already overworked developer.
- Developers jump ship unable to take the heat and the work load.
- Suggestion of re-coding the project which is often done and then it goes okay again for a while – repeating the cycle.
It is usually at this point that an Architect or outsource company is contracted in to come and help sort this mess out. Now they have to explain what is going on…
As I always say a bad process is always better than no process and an outsourced company will most likely make some suggestions around a methodology and some process changes but this will only help you so far. A process will not make any difference to the integrity of your software.
The truth is to have integrity and stability in your software you need a process for the people and you need someone to look after the software. This person is the architect.
Can this project be saved?
The answer is usually, No, not without making major changes and this is a bitter pill for management of a company to swallow. They have invested millions in the project, the project is already delayed and they have clients on a previous version waiting for an update.
What adds even more to the situation is that they are usually not technically able to comprehend why the developers can’t just fix it.
Walking away from the project to start new or having to wait even longer for some structure changes are not easy to accept and often this is the downfall of startup companies that need to push out more and more features to grow their client base.
The reality is that the amount of energy spent to create this complexity over months and years can not easily be unraveled or simplified.
It’s like trying to filter the milk out from your already made cup of coffee.
So where to from here?
It’s best to shelve the existing version, keep your customers on it and do as little as possible to the old version while focusing all effort in doing the project in a new way.
Another suggestion is to keep maintaining the code base but doing all new development in a with a new method to try and simplify the system. (I will cover how later)
How do we reduce complexity and provide integrity.
The answer is simple but it takes strict discipline.
- You need to plan and design. slow down. 80% planning and 20% coding. In all industries people spent most of the time planning but for some reason in the software industry people want to skip this step.
To win the war generals need to plan and have strategy.
- Limit and control the technology in you application. By doing this you will reduce complexity and maintenance and the learning curve for new developers to start on it. Beware of the open source world, many different technologies and security vulnerabilities. Developers always wants to work on the latest coolest tech and within a year or two its no longer supported.
Have one person in control of the technology. Let them decide if its going in or not.
- Reduce the size of the application by reducing it in smaller sub systems and fewer components! Look at micro services. This sounds ridiculous but if you reduce the size of the code base, by reducing the number relationships between structures the application will become simpler. If you reduce the number of developers that work on the project it will also become simpler to work on.
Restructure the application. No, I am not saying go and code in a single file.
- Reduce an application into smaller isolated parts that represent isolated sub application themselves. Do not allow or limit code-reuse between these sub systems. Limit developers to working within specific teams.
Shocking as that might be – do not code for reuse.
- Have smaller dedicated teams working on smaller parts of the application. This approach will allow the smaller applications to evolve separately not having an impact on the other parts of the system. It will reduce the complexity of the code base and reduce the learning curve in each of the the sub systems. As a result delivery will speed up.
Keep your coding standards but don’t over complicate it.
In my next article, Volatility based decomposition for Microservices I will show you one possible way to do it.
If you believe that your process will help you – read this – agile-software-development
Good article, well written.
I agree that standards, (add whatever buzzwords you want here…) won’t save your project.
Having said that, standards can help improve maintainability on large projects. (http://scottdorman.github.io/2007/06/29/Why-Coding-Standards-Are-Important/)
Standards should:
– be considered from day one;
– continually be revisited and refined throughout a project’s lifecycle;
We shouldn’t:
– think of standards as magic dust to be sprinkled on a failed project;
– become emotionally attached to standards; https://medium.com/@ameet/strong-opinions-weakly-held-a-framework-for-thinking-6530d417e364
– become stringent standard enforcers;
We should strive to:
– have strong opinions, weakly held;
– have the project’s best interests at heart;
– embrace change and continually reflect on the validity of standards;
– help others understand why standards are there in the first place, context is crucial;
– stay objective, leave emotions out of it;
Inheritance is often the only tool a developer considers when trying to apply the DRY principle. http://joelabrahamsson.com/the-dry-obsession/
I agree with your stance on outsourcing, if your own team can’t solve problems and make things work, how will someone that probably don’t understand your business that well?
What saves a project is people taking ownership, working together and using it as an opportunity to learn and grow.
Good point on just keeping the existing version alive, and focusing all your energy on the next version.
There’s no point in trying to improve the old code, you run the risk of introducing bugs, especially if you don’t have unit tests. https://medium.com/javascript-scene/5-common-misconceptions-about-tdd-unit-tests-863d5beb3ce9
Off topic, but the internet spaghetti image made me think of an interesting talk by Greg Young on being productive in a project in 24h. https://www.youtube.com/watch?v=KaLROwp-VDY